BoredNet
Di recente mi sono imbattuto nel paradigma Joint Embedding Predictive Architecture (JEPA) applicato in vari contesti. La principale area di applicazione è il campo visivo, e le architetture JEPA si differenziano dalle altre perchè spostano il ragionamento in un livello più astratto. Non tentano di ricostruire la patch mancante di una immagine pixel per pixel, ma sono ideate per prevedere una rappresentazione latente del pezzo mancante di una immagine. Essendo un'architettura self supervised, permette di sfruttare dati non etichettati ed in alcuni lavori di ricerca recenti viene usato come backbone nei Vision Language Models.
L'idea dietro i JEPA è applicabile anche al di fuori dei task strettamente visivi, ed un lavoro che mi ha suscitato parecchio interesse è LeWorldModel. Sostanzialmente, LeWorldModel è un world model capace di risolvere diversi task senza una funzione di reward esplicita durante il training. Questo significa che non è necessario modellare il task da risolvere come un problema classico di reinforced learning usando una funzione di reward. La loro architettura viene addestrata con lo scopo di far conoscere alla rete le regole fisiche del task che andrà a risolvere. Una volta apprese, alla rete viene dato lo stato finale da raggiungere e autonomamente è in grado di pianificare le azioni necessarie per passare dallo stato di partenza allo stato richiesto.
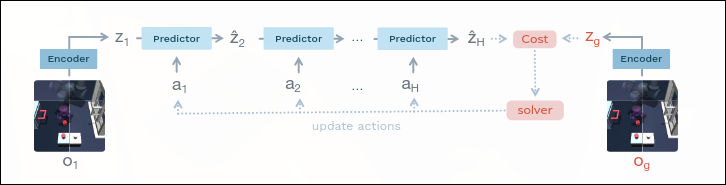
È un approccio estremamente interessante, perchè si avvicina ad un modo di ragionare più umano, anche se ci sono diversi paletti. Primo fra tutti, la rete va addestrata comunque su un task specifico, e non è in grado di generalizzare. Si ipotizza che una rete JEPA-based addestrata su sufficienti dati sia in grado di generalizzare, ma ad oggi non è ancora stato provato. In secondo luogo, alla rete è data una posizione finale da raggiungere, e quindi un obiettivo esplicito.
Ragionando su questo lavoro, mi sono chiesto quanto sarebbe interessante riuscire a creare un sistema capace di generalizzare quel tanto che basta per riuscire a completare task in un qualsiasi mondo virtuale proposto. Mi sono venuti subito in mente i videogiochi, perchè sono il campo di prova ideale per un task del genere. Pensandoci, ogni videogioco è comandabile tramite un insieme limitato di azioni (basti pensare ai tasti di un controller) ed il mondo di gioco è ben definito e prevedibile. Quanto sarebbe difficile, in questo contesto, riuscire a creare una rete capace di apprendere un qualsiasi gioco semplicemente giocando, senza specificare un obiettivo finale?
Mi rendo conto che mi sto avvicinando alla fantascienza, però ragionando un attimo oggigiorno abbiamo delle reti in grado di simulare un "ragionamento", ossia i Large Language Model. Se esistesse un modo per unire la pseudo conoscenza umana di un LLM con l'abilità di poter vedere ed interagire con un mondo virtuale, teoreticamente qualcosa si dovrebbe riuscire ad ottenere.
Prima però di creare Skynet nel garage di casa, facciamo un passo indietro. Ho detto che LeWorldNet ha due paletti: il training specifico per imparare ad interagire con un dato mondo e l'obiettivo esplicito da raggiungere. Con BoredNet voglio provare a togliere il secondo paletto. Mi piacerebbe riuscire a creare un sistema capace di raggiungere un obiettivo senza che gli venga detto esplicitamente.
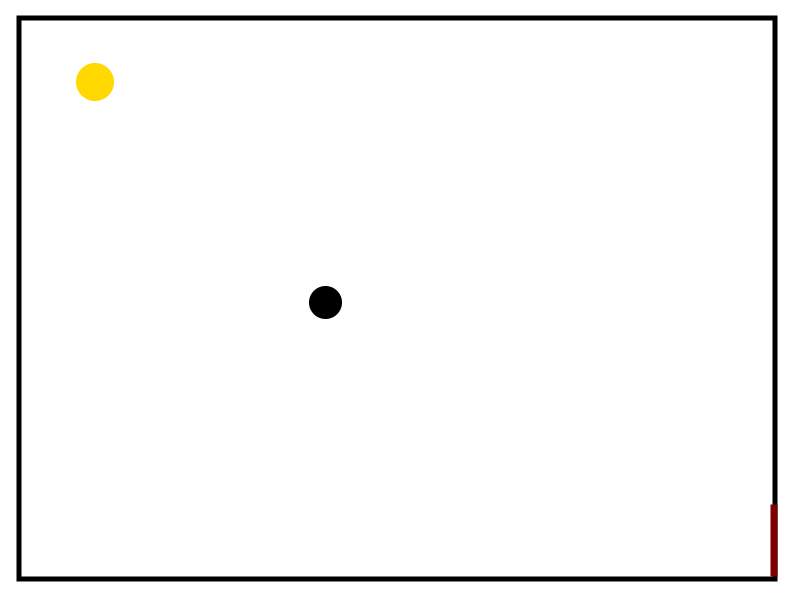
Il task da risolvere è semplice ma diviso in due step. L'agente (rappresentato dal pallino nero) deve uscire dalla stanza (porta marrone). Per farlo però deve prima raccogliere la chiave. In questa prima versione del gioco, l'agente vede tutta la stanza e ha conoscenza totale del sistema. In caso riuscissi a risolvere il task, mi piacerebbe generalizzare a stanze più grandi del campo visivo dell'agente, ma questo introduce diverse altre sfide a cui penserò a tempo debito.
Sperando di non abbandonare il progetto dopo due settimane, ci risentiamo nel prossimo post nel quale formalizzerò meglio il mondo di gioco ed il task da risolvere.
Nota: non ho ancora fatto una ricerca bibliografica estensiva su questo campo, quindi potrei aver detto inesattezze o fesserie. È tutto da prendere con le pinze, però volevo cimentarmi in qualcosa di nuovo e JEPA + RL sembra un campo molto interessante e stimolante